embedding 是一种把文本转换为更低维的数据(向量)的方法。
我在 azure 新建了一个 embedding 模型,这里尝试调用获取一个词的向量数据:
1 | embedding1 = openai.Embedding.create( |
发现返回的向量列表数据比较多,是因为“苹果”有很多不同的语义。
1 | [0.011903401464223862, -0.023080304265022278, -0.0015027695335447788, -0.020565500482916832, 0.005127404350787401, ...省略..., 0.037833817303180695, -0.013489124365150928, -0.005326492711901665, 0.008648128248751163, 0.010219880379736423] |
可以通过 np.dot 方法计算两个向量间的关联性,数值越高表示关联性越近。
1 | print(np.dot(embedding1, embedding2)) |
可以用这种技术来做相关性推荐,比如YouTube的视频推荐、Twitter的timeline、Spotify的歌曲推荐。
也就是:内容降维向量、计算向量相关性、推荐高相关性数据。
然而也可以尝试用来做聊天机器人(因为如果用微调训练模型,训练一次成本也不低,最后有可能训练出来的新模型不尽人意还要再次调整数据进行训练),思路:用户提出问题 - 搜索相似向量 - 提取向量对应文本 - 让GPT润色 - 得到结果。
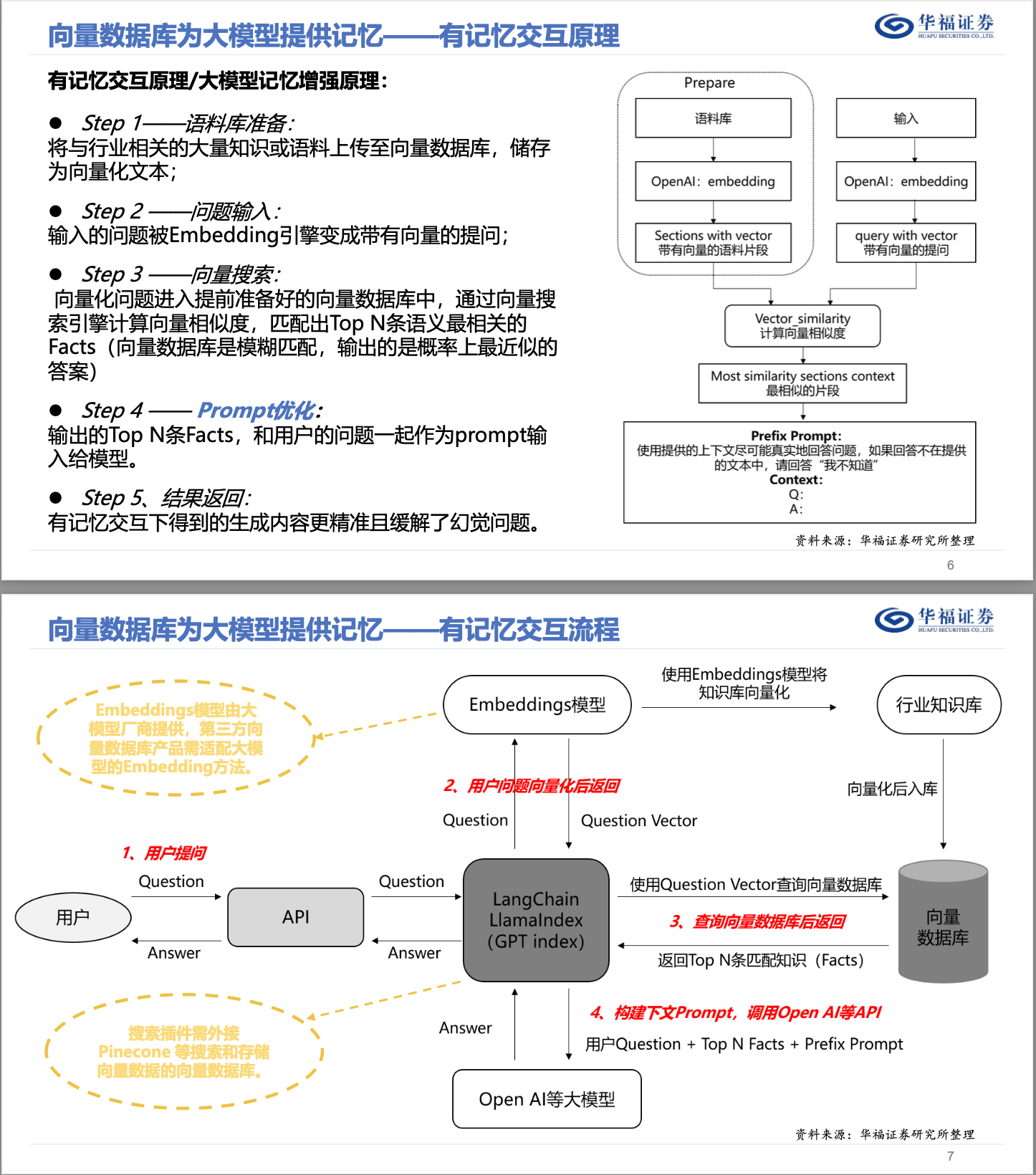
当接收到用户问题,就把问题转换成向量,然后在向量数据库中寻找相似值,找到后,再找到对应的数据,然后取出来请求GPT API让润色,返回润色结果给用户。
例如这个项目,就是一个很好的例子:https://github.com/GanymedeNil/document.ai
但注意,数据源需要是文本,例如文章那种数据。如果是数字比较多的,例如XX编号的那种常规业务数据,不太容易精准查询到。